大模型LLM在Text2SQL上的应用实践
前言
目前,大模型的一个热门应用方向Text2SQL,它可以帮助用户快速生成想要查询的SQL语句,再结合可视化技术可以降低使用数据的门槛,更便捷的支持决策。本文将从以下四个方面介绍LLM在Text2SQL应用上的基础实践。
· Text2SQL概述
· LangChain基础知识
· 基于SQLDatabaseChain的Text2SQL实践
· 后续计划
Text2SQL概述
Text-to-SQL(或者Text2SQL),顾名思义就是把文本转化为SQL语言,更学术一点的定义是:把数据库领域下的自然语言(Natural Language,NL)问题,转化为在关系型数据库中可以执行的结构化查询语言(Structured Query Language,SQL),因此Text-to-SQL也可以被简写为NL2SQL。
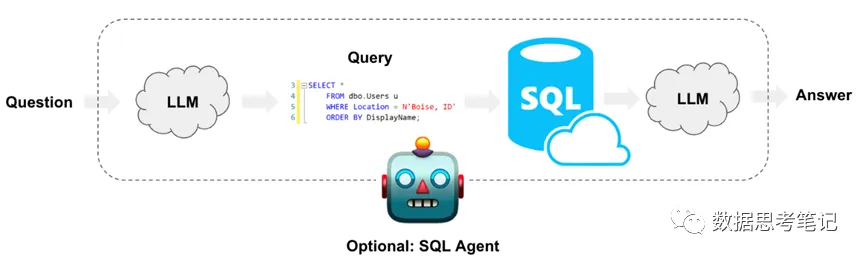
· 输入:自然语言问题,比如“查询表t_user的相关信息,结果按id降序排序,只保留前10个数据 ”
· 输出:SQL,比如 “SELECT \ FROM t_user ORDER BY id DESC LIMIT 10*”
Text2SQL应用主要是帮助用户减少开发时间,降低开发成本。“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
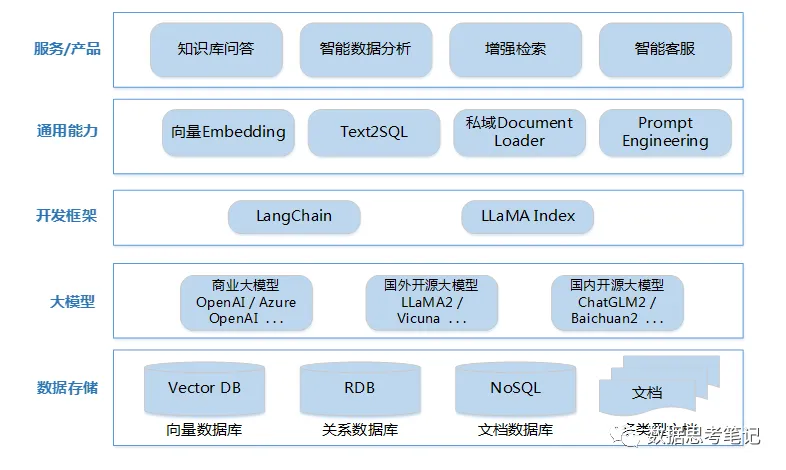
基于LLM的应用开发基本架构如上图,本文介绍以LangChain + OpenAI + RDB的方式来实现Text2SQL的实践方案。
LangChain基础知识
LangChain是一个面向大语言模型的应用开发框架,如果将大语言模型比作人的大脑,那么可以将LangChain可以比作人的五官和四肢,它可以将外部数据源、工具和大语言模型连接在一起,既可以补充大语言模型的输入,也可以承接大语言模型的输出。
LangChain提供各种不同的组件帮助使用LLM,如下图所示,核心组件有Models、Indexes、Chains、Memory、Prompt以及Agent。
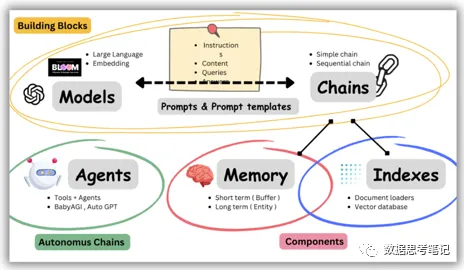
3.1 Models
LangChain本身不提供LLM,提供通用的接口访问LLM,可以很方便的更换底层的LLM以及自定义自己的LLM。主要有2大类的Models:
1)LLM:将文本字符串作为输入并返回文本字符串的模型,类似OpenAI的text-davinci-003
2)Chat Models:由语言模型支持将聊天消息列表作为输入并返回聊天消息的模型。一般使用的ChatGPT以及Claude为Chat Models。
与模型交互可以通过给予Prompt的方式,LangChain通过PromptTemplate的方式方便我们构建以及复用Prompt。
代码示例如下:
from langchain import PromptTemplate
# 定义提示模板
prompt = PromptTemplate(input_variables=["question"], template="""
简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}""",)
print(prompt.format_prompt(question="如何进行数据治理"))3.2 Indexes
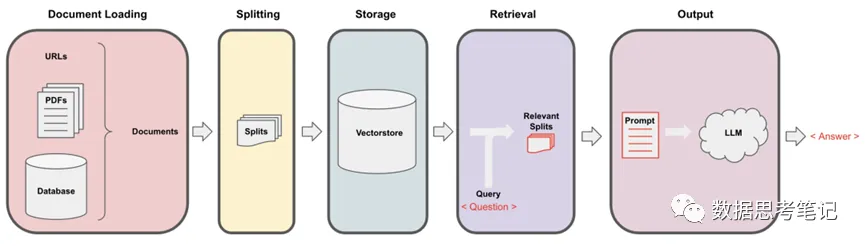
索引和外部数据进行集成,用于从外部数据获取答案。如下图所示,主要的步骤:
· 通过Document Loaders加载各种不同类型的数据源
· 通过Text Splitters进行文本语义分割
· 通过Vectorstore进行非结构化数据的向量存储
· 通过Retriever进行文档数据检索
3.3 Chains
LangChain通过chain将各个组件进行链接,以及chain之间进行链接,用于简化复杂应用程序的实现。其中主要有LLMChain、SQLDatabase Chain以及Sequential Chain。
3.3.1 LLMChain
最基本的链为LLMChain,由PromptTemplate、LLM和OutputParser组成。LLM的输出一般为文本,OutputParser用于让LLM结构化输出并进行结果解析,方便后续的调用。

其实现原理如图所示,包含三步:
· 输入问题
· 拼接提示,根据提示模板将问题转化为提示
· 模型推理,输出答案
代码如下所示:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "Your openai key"
# 定义模型
llm = OpenAI(temperature=0)
# 定义提示模板
prompt = PromptTemplate(input_variables=["question"], template="""
简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。
问题是:{question}""",)
# 定义chain
chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
# 执行chain
print(chain.run("如何开展数据治理"))3.3.2 SQLDatabaseChain
SQLDatabaseChain能够通过模型自动生成SQL并执行,其实现原理如图所示,包含如下过程:
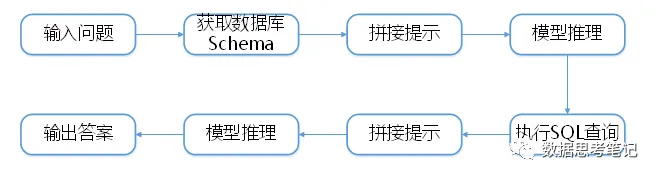
· 输入问题;
· 获取数据库Schema,Schema包含数据库所有表的建表语句和数据示例,LangChain支持多种关系型数据库,包括MariaDB、MySQL、SQLite、ClickHouse、PrestoDB等;
· 拼接提示,根据提示模板将问题、数据库Schema转化为提示,并且提示中包含指示,要求模型在理解问题和数据库Schema的基础上,能够按一定的格式输出查询SQL、查询结果和问题答案等;
· 模型推理,这一步预期模型根据问题、数据库Schema推理、输出的答案中包含查询SQL,并从中提取出查询SQL;
· 执行查询SQL,从数据库中获取查询结果;
· 拼接提示,和上一次拼接的提示基本一致,只是其中的提示中包含了前两步已获取的查询SQL、查询结果;
· 模型推理,这一步预期模型根据问题、数据库Schema、查询SQL和查询结果推理出最终的问题答案。
3.3.3 SequentialChain
SequentialChains是按预定义顺序执行的链。SimpleSequentialChain为顺序链的最简单形式,其中每个步骤都有一个单一的输入/输出,一个步骤的输出是下一个步骤的输入。SequentialChain为顺序链更通用的形式,允许多个输入/输出。
3.4 Memory
正常情况下Chain无状态的,每次交互都是独立的,无法知道之前历史交互的信息。LangChain使用Memory组件保存和管理历史消息,这样可以跨多轮进行对话,在当前会话中保留历史会话的上下文。Memory组件支持多种存储介质,可以与Mongo、Redis、SQLite等进行集成,以及简单直接形式就是Buffer Memory。
3.5 Agent
Agent字面含义就是代理,如果说LLM是大脑,Agent就是代理大脑使用工具Tools。目前的大模型一般都存在知识过时、逻辑计算能力低等问题,通过Agent访问工具,可以去解决这些问题。目前这个领域特别活跃,诞生了类似AutoGPT、BabyAGI、AgentGPT等一堆优秀的项目。传统使用LLM,需要给定Prompt一步一步地达成目标,通过Agent是给定目标,其会自动规划并达到目标。
基于SQLDatabaseChain的Text2SQL实践
4.1 简介
LangChain提供基于LLM的SQLDatabaseChain,可以利用LLM的能力将自然语言的query转化为SQL,连接DB进行查询,并利用LLM来组装润色结果,返回最终answer。
在后台,LangChain 使用SQLAlchemy连接到 SQL 数据库。因此,SQLDatabaseChain可以与 SQLAlchemy 支持的任何 SQL 方言一起使用,例如 MS SQL、MySQL、MariaDB、PostgreSQL、Oracle和 SQLite。
4.2 数据准备
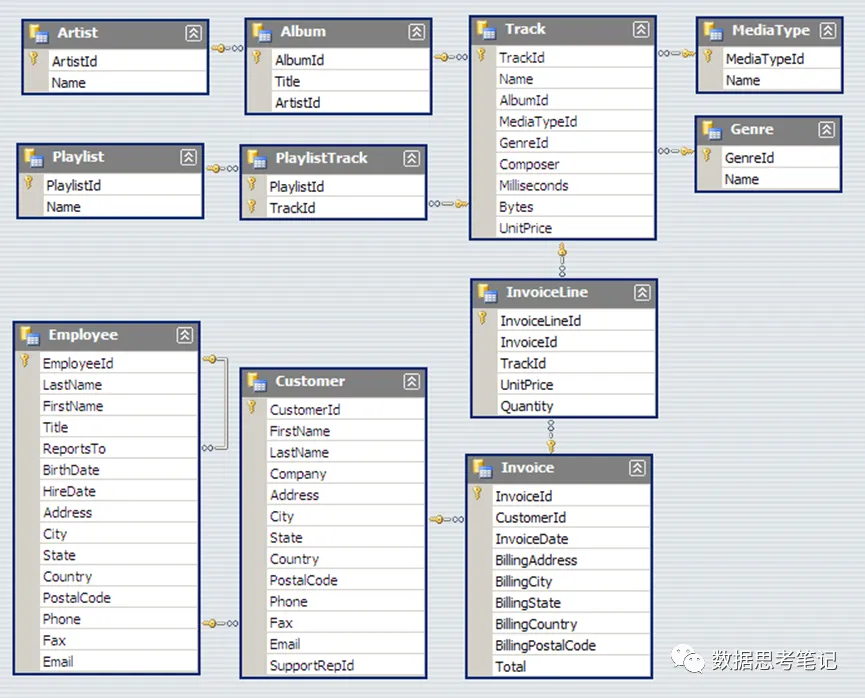
本案例使用SQLite 和示例Chinook 数据库,用户可按照https://database.guide/2-sample-databases-sqlite/ 上的说明进行设置。Chinook表示一个数字多媒体商店,包含了顾客(Customer)、雇员(Employee)、歌曲(Track)、订单(Invoice)及其相关的表和数据,数据模型如下图所示。
4.3 实践过程
需求:测试中文提问“总共有多少员工?”,即英文提问“How many employees are there?”
期望:模型先给出查询Employee表记录数的SQL,再根据查询结果给出最终的答案。
(1)测试中文提问,代码如下所示:
from langchain.llms import OpenAI
from langchain.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
import os
os.environ["OPENAI_API_KEY"] = "Your openai key"
db = SQLDatabase.from_uri("sqlite:///..../Chinook.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("总共有多少员工?")输出结果如下:
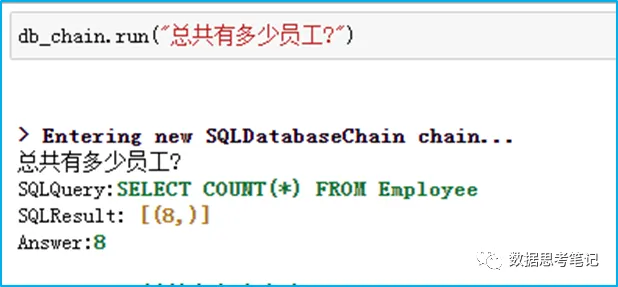
这里我们使用商业化的OpenAI,并将其temperature设为0,因为查询DB不太需要创造性和多样性。从返回的过程来看,自然语言被翻译成了SQL,得到查询结果后,解析包装结果,最终返回我们可以理解的答案。这里LLM成功将“总共”转成select count(*),并准确地识别出表名,且最终组装出正确的结果。
注意:对于数据敏感项目,可以在 SQLDatabaseChain 初始化中指定 return_direct=True,以直接返回 SQL 查询的输出,而无需任何其他格式设置。这样可以防止 LLM 看到数据库中的任何内容。但请注意,默认情况下,LLM 仍然可以访问数据库方案(即所用方言、表名和列名)。
(2)测试英文提问,也可以得到我们想要的结果:
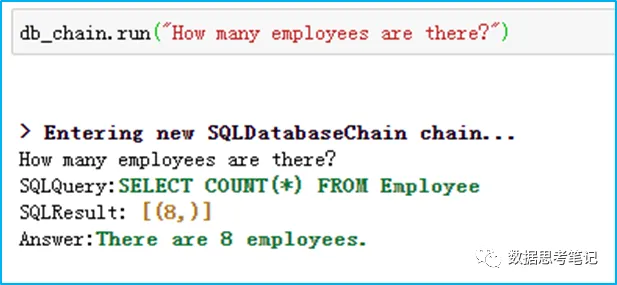
通过上例,我们可以借助LangChain提供的SQLDatabaseChain,轻松地连接LLM与Database,自然语言的方式输入,自然语言的方式输出,借助LLM的强大能力来理解问题、生成SQL查询数据并输出结果。
五、后续计划
随着大模型的发展,LangChain是目前最火的LLM开发框架之一,能和外部数据源交互、能集成各种常用的组件等等,大大降低了LLM应用开发的门槛。基于SQLDatabaseChain实现的Text2SQL只是最基础的实践方式,但对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉问题、数据安全问题。如何解决或减少该类问题的出现,可改进的措施和方案在后续专题中继续讨论,大家一起群策群力。总之,实现高稳定、高可靠的基于LLM的应用,是一个持续改进的过程,是一个多种技术相结合的过程。



