图解Transformer工作原理
前言
Transformer 已经成为了前沿人 AI 技术的代名词,尤其是在自然语言处理(NLP)这一领域。
那么,是什么使得 Transformer 能够如此高效准确地掌握语言的复杂性呢?
让我们一起深入探索 Transformer 架构的核心原理。
但在此之前,不妨先看看它的应用场景。无论是你使用的谷歌翻译还是** ChatGPT,它们背后的强大功能都离不开 Transformer**。
谷歌翻译:这个被广泛使用的工具在很大程度上依靠 Transformer 技术,实现了对超过 100 种语言的快速准确翻译。它能够考虑到整个句子的上下文,而非仅仅是单个词语,使得翻译结果更加自然流畅。
Netflix 推荐系统:Netflix 是如何精准推荐你可能喜欢的电影和电视剧的?答案是通过分析你的观看历史和其他用户的数据,Transformer 能够识别出模式和联系,最终向你推荐个性化的内容。
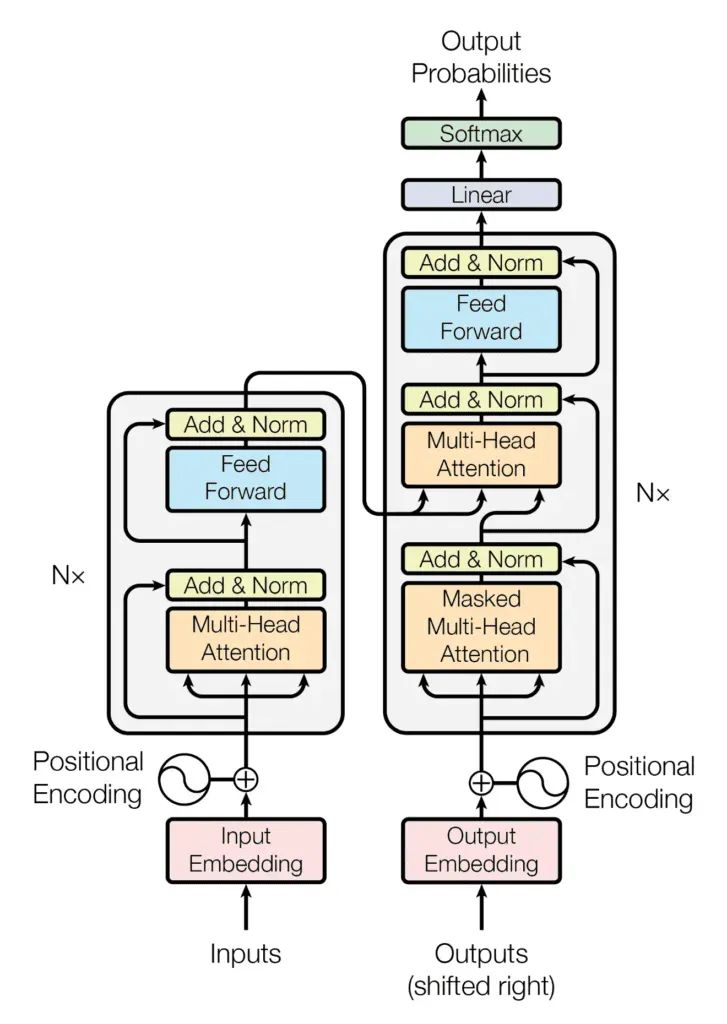
概览:编解码器交响
想象一个特殊的工厂,它不是在组装物理产品,而是在加工处理语言。这个工厂主要由两个部分组成:
- 编码器(Encoder):它负责提取信息,通过细致分析输入文本,理解文本中各个元素的含义,并发现它们之间的隐藏联系。
- 解码器(Decoder):依托编码器提供的深入洞察,解码器负责生成所需的输出,无论是将句子翻译成另一种语言、生成一个精确的摘要,还是创作一首全新的诗歌。
编码器:解码输入迷宫
编码器的旅程从 “输入嵌入” 开始,此过程中,每个单词都从文本形态转换为数值向量,就好像给每个单词配上了一个独一无二的身份证。
以这个例子为例:
输入文本:例如,“The cat sat on the mat.”
在输入嵌入层,每个单词都被翻译成一个数值向量,就像在一个庞大的字典里,每个单词都有一个对应的 “向量地址”。
这些向量不仅捕捉了单词的含义,还包括:
- 语义关系(比如,“cat” 和 “pet” 更近,而不是和 “chair”);
- 句法角色(比如,“cat” 通常作为名词,“sat” 作为动词);
- 句中上下文(比如,这里的 “mat” 很可能是指地垫)。
向量表示如下:
- “The” -> [0.2, 0.5, -0.1, …]
- “cat” -> [0.8, -0.3, 0.4, …]
- “sat” -> [-0.1, 0.7, 0.2, …]
但编码器的工作远不止于此,它还使用了一些关键技术来进一步深入。
自注意力机制是其中的革命性创新。想象为对每个单词打开一束聚光灯,这束光不仅照亮了该单词,还揭示了它与句中其他单词的联系。这让编码器能够理解文本的全貌 —— 不只是孤立的单词,还有它们之间的联系和细微差别。

再次以句子 “The quick brown fox jumps over the lazy dog.” 为例:
首先,每个单词都转换成了一个数值表示,称为 “词嵌入”,就像在一个巨大的词库地图上给每个单词定位。
接下来,自注意力机制为每个单词生成了三个特殊的向量:“查询(Query)”(询问我需要什么信息)、“键(Key)”(标示我有什么信息)和 “值(Value)”(实际的含义和上下文)。
然后,通过比较每个单词的 “查询” 向量与其他所有单词的 “键” 向量,自注意力层评估了各个单词之间的相关性,并计算出注意力得分。这个得分越高,表示两个单词之间的联系越紧密。
最后,自注意力层根据注意力得分加权处理 “值” 向量,这就像根据每个单词与当前单词的相关度,取了一个加权平均值。
通过考虑句中其他单词提供的上下文,自注意力机制为每个单词创建了一个新的、更丰富的表示。这种表示不仅包含了单词本身的含义,还有它如何与句中其他单词关联和受到影响。
多头注意力机制(Multi-Head Attention)可以被理解为有多个分析小组,每个小组关注于词与词之间联系的不同层面。这使得编码器能够全面捕获词义之间的多元关系,从而深化其对语句的理解。
还是以句子:“The quick brown fox jumps over the lazy dog.”为例。
在多头注意力机制中,不同于只使用一个自我关注机制,我们有多个独立的 “头部”(通常是 4 到 8 个)。每个头部都针对每个词分别维护一套查询(Query)、键(Key)和值(Value)向量。
这种机制下的注意力是多样化的:每个头部根据不同的逻辑计算注意力得分,聚焦于词间关系的不同方面:
- 一个头部可能专注分析语法角色,比如 “fox” 和 “jumps” 之间的关系。
- 另一个可能关注词序,比如 “the” 和 “quick” 之间的顺序。
- 还有的头部可能识别同义词或相关概念,例如将 “quick” 和 “fast” 视为相近的词。
通过结合这些不同头部的观点,每个头部的输出被汇总,综合不同的洞察力。
最终,这种综合的表示形式包含了对句子更加丰富的理解,涵盖了词与词之间的多样化关系,而不仅仅是单一视角。
位置编码(Positional Encoding)是为了补充 Transformer 无法直接处理词序的不足,加入了每个词在句中位置的信息。可以想象成给每个分析员一张地图,指示他们应该如何按顺序审视词汇。
继续以句子:“The quick brown fox jumps over the lazy dog.” 为例,来看位置编码是如何工作的:
首先,每个词(如 “The”,“quick” 等)都被转换成一个唯一的数字向量,这就是所谓的单词嵌入,可以看作是在庞大的词库中为每个词分配的唯一标识。
接着,每个词的嵌入会和一个基于其在句中位置计算出的额外向量结合。这些位置向量通过正弦和余弦函数生成,能够反映词之间的远近关系。
- 低频波动揭示词之间的长距离关系。
- 高频波动则关注紧密相连的词。
这样,每个词的原始向量与其位置向量相加,形成了一个既含有词义也含有位置信息的新向量。
即便句子的顺序变化,位置向量也能保持词之间的相对位置关系,使得模型能准确理解词与词之间的连接。
前馈网络(FFN,Feed Forward Network)为模型增添了一层非线性处理,使其能够学习到更为复杂的单词间关系,这些关系可能单凭注意力机制难以捕捉。
通过前面几层的分析,你已经深入理解了句中单词的含义、它们之间的联系以及它们的位置。现在,FFN 就像是一只侦探用的放大镜,准备揭示那些不立即显现的复杂细节。
FFN 通过以下三个关键步骤来实现这一目标:
- 非线性变换:FFN 通过使用 ReLU 等非线性函数来增加信息的复杂性,而非直接进行简单计算。可以想象它为现有信息施加了一个特殊的滤镜,揭露了那些简单运算可能忽视的隐藏模式和联系。这使得 FFN 能够把握词与词之间更加细腻的关系。
- 多层次分析:FFN 不是单一步骤,而是通常由两层或更多的全连接层组成。每一层都在前一层的基础上进一步转换信息,就像你在不断放大镜下审视句子,每一层都揭示出更多细节。
- 维度变换:在第一层,FFN 将信息维度扩展(如从 512 维扩到 2048 维),以便分析更多特征并捕捉更复杂的模式。这就像是在更大的画布上展开信息进行深入审查。随后,在最终层将信息维度缩减回原始大小(比如又回到 512 维),确保与后续层的兼容性。
应用到我们的句子上:
想象 FFN 帮助识别 “quick” 和 “brown” 不仅描述了 “fox”,还通过它们联合的含义巧妙地与 “fox” 的速度感联系起来。
或者,它可能深入探究 “jumps” 和 “over” 之间的关系,理解这个动作和空间关系,超越了它们单独的定义。
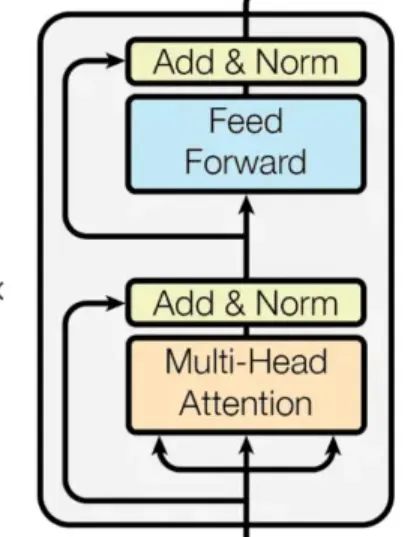
重复、优化、再重复:自注意力、多头注意力等层被叠加并多次重复。每一次迭代,编码器都在精细化其对输入文本的理解,构建出一个全面的文本表征。
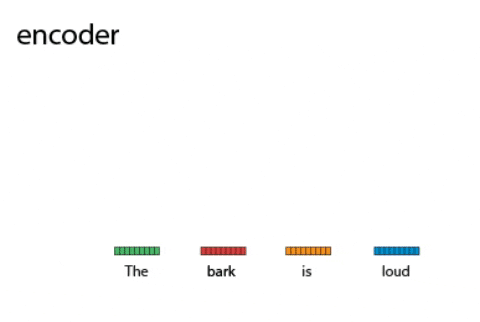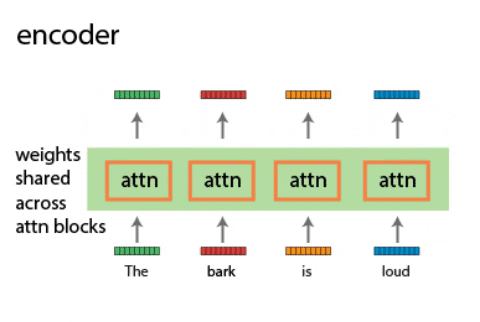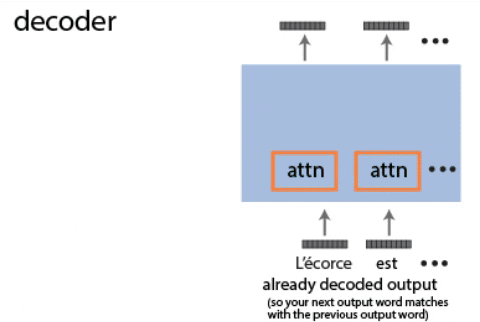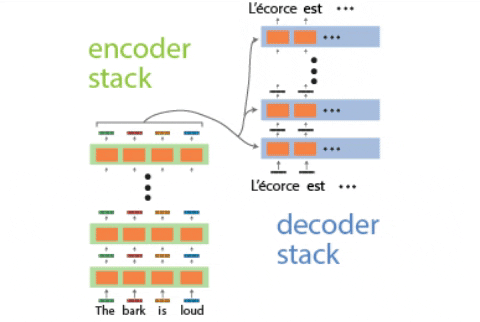
解码器:编织输出挂毯
现在,轮到解码器承担任务。与编码器不同的是,解码器面临着额外的挑战:在不预见未来的情况下,逐字生成输出。为此,它采用了以下策略:
- 掩蔽自注意力:类似于编码器的自注意力机制,但有所调整。解码器仅关注之前已生成的单词,确保不会利用到未来的信息。这就像是一次只写出一个句子的故事,而不知道故事的结局。
- 编码器 - 解码器注意力:这一机制允许解码器参考编码好的输入,就像写作时回头查看参考资料一样。这确保了生成的输出与原始文本保持一致性和连贯性。
- 多头注意力和前馈网络:与编码器相同,这些层帮助解码器深化对文本中上下文和关系的理解。
- 输出层:最终,解码器将其内部表征逐一转化为实际的输出单词。这就像是最后的装配线,把所有部件组合起来,形成期望的结果。
超越基本概念
请记住,这只是 Transformer 世界迷人之处的一瞥。具体的架构会根据任务和数据集的不同而有所变化,包括不同数量的层和配置。
此外,每一层涉及的复杂数学运算超出了本解释的范围。
但希望这能让你基本理解 Transformer 如何工作,以及它们是如何彻底改变自然语言处理(NLP)领域的。
因此,当你下次遇到流畅的机器翻译或对 AI 驱动的文本生成器的创意赞叹时,请记住 Transformer 内部编码器与解码器之间的精妙互动,它们是如何通过注意力机制和并行处理技术共同织就这场魔法的。
论文链接:https://arxiv.org/abs/1706.03762
原文链接:https://nintyzeros.substack.com/p/how-do-transformer-workdesign-a-multi



