金融大模型技术创新与应用探索
大模型时代已来临,每个组织以及每个人的知识体系都需要重塑,思考如何更好地利用 AI 工具提升效率,以应对未来的变化。而始终不变的是,我们要持续学习,时刻保持好奇心,以不变应对未来更多的变化。本文将分享金融行业对大模型技术的探索与实践。
*主要内容包括以下几大部分 *
- 从通用大模型到金融大模型
- 金融大模型的训练技术创新
- 金融大模型的评测方法创新
- 金融大模型的应用实践创新
- 总结:金融大模型迭代路径
01 从通用大模型到金融大模型
1.大模型涌现超预期能力,有望为金融行业创造价值增量
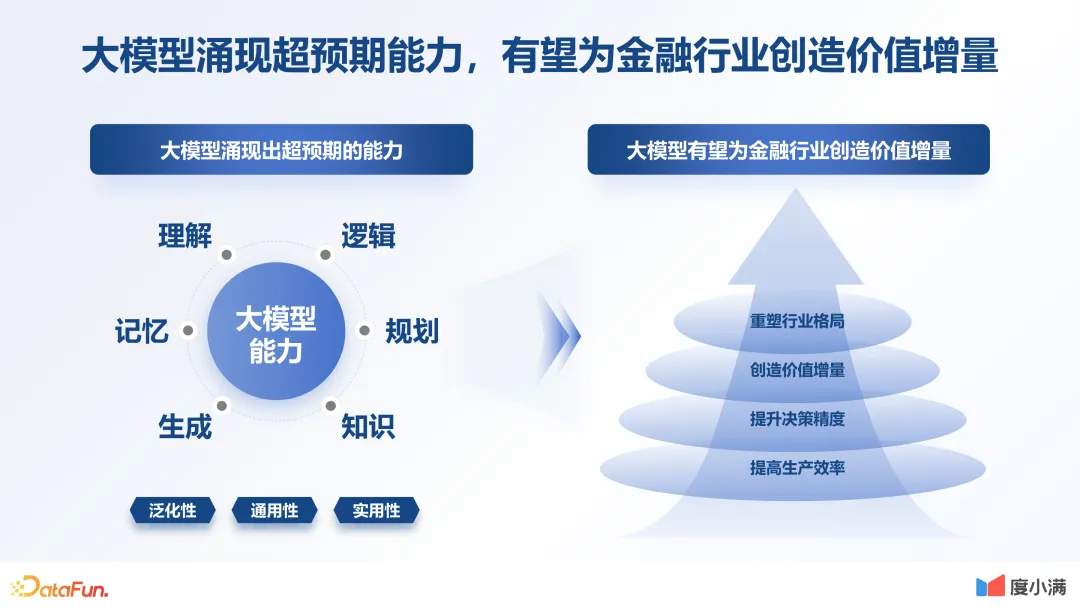
金融行业具有三大特性:
- 数据驱动:金融是一个关于数据的生意,所有的决定都需要通过分析数据来做决策。
- 高度知识化密集产业:金融是一个高度知识化密集的行业,有非常多的专业领域知识,不在这一行业中的人是很难知道的。另外,金融内部也有理财、保险、信贷等不同的细分领域,知识结构复杂密集。
- 业务流程极其复杂:金融是需要非常多人工去协作的一个产业,业务流程极其复杂。
这三个特性其实跟大模型本身的逻辑理解记忆等能力是非常匹配的。所以我们一直认为金融领域是一个天然的大模型的最佳应用场景。我们也希望通过探索为金融行业带来更多的价值增量。
2.通用模型难胜任金融任务,大模型落地金融面临挑战

我们为什么需要一个金融行业自己的大模型呢?因为当前通用模型的能力还存在缺陷。主要包括以下三个方面:
- 金融知识挑战:金融行业有自己领域内的专业知识,比如 KS、MOB、COB 等专业术语,通用大模型可能不了解。
- 金融能力挑战:大模型目前还存在幻觉问题、计算准确性问题、遗忘问题等。金融行业是数据驱动的业务,对数据准确性要求比较高,通用大模型存在的这些问题无法满足金融行业的需求。
- 应用成本挑战:通用模型的成本相对较高,我们希望通过行业模型去降低应用成本。
基于以上三个挑战,我们认为做金融领域的行业大模型是非常有必要的。
3.面对成本挑战,专项增强的领域模型更显高性价比
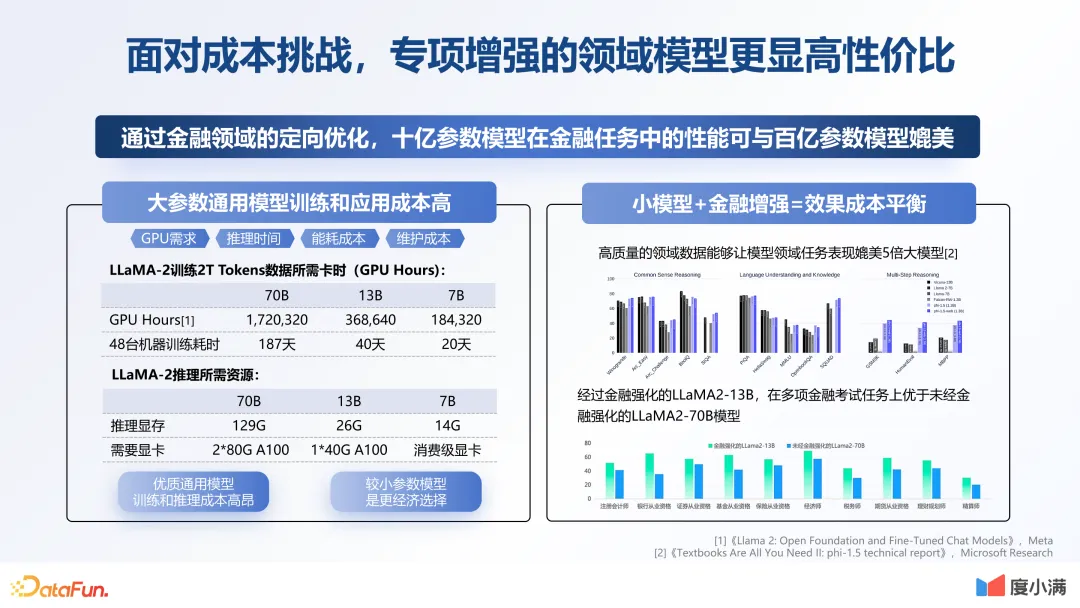
上图左边的基础数据源自 meta 论文。可以看到,LLaMA-2 模型训练 2T tokens,用 A100 大概需要多少时间。如果参数是 70B,原论文里写的是需要 172 万卡时,折成 48 台 A100 机器,就需要 187 天,也就是半年的时间,这还是在训练过程中没有任何训练故障,训练效率和效果没有任何反复的情况下的一个时间。假设中间有一些机器发生故障,或者效果不及预期需要迭代,那用 48 台 A100 机器训练,可能就需要一年时间。这个训练成本对于很多企业来讲是极其昂贵的。
再来看下推理的资源,如果是一个 70B 的大模型,它所需要显卡内存是 129G,也就是需要两张 A100。所以对于大多数企业来讲,通用模型的训练和推理成本是非常高昂的。
上图右边是行业大厂的一些探索。比如微软有一篇论文提到,一个高质量的领域数据,能够让模型表现出比它参数大五倍的模型相近的效果。这一点很容易理解,如果把大模型当成一个人,一个天赋一般的选手,通过后天的不断努力,并且只专心某一个行业,那他在这个行业取得的成就可能会比天赋好的人更高。比如一个 13B 模型通过不断调优,它在金融领域内某个场景的效果会比通用的 70B 的效果更好。所以我们希望用一个更小的模型,通过不断学习行业知识,达到一个更大模型的效果。
4.为解决通用模型不胜任问题,自研金融大模型
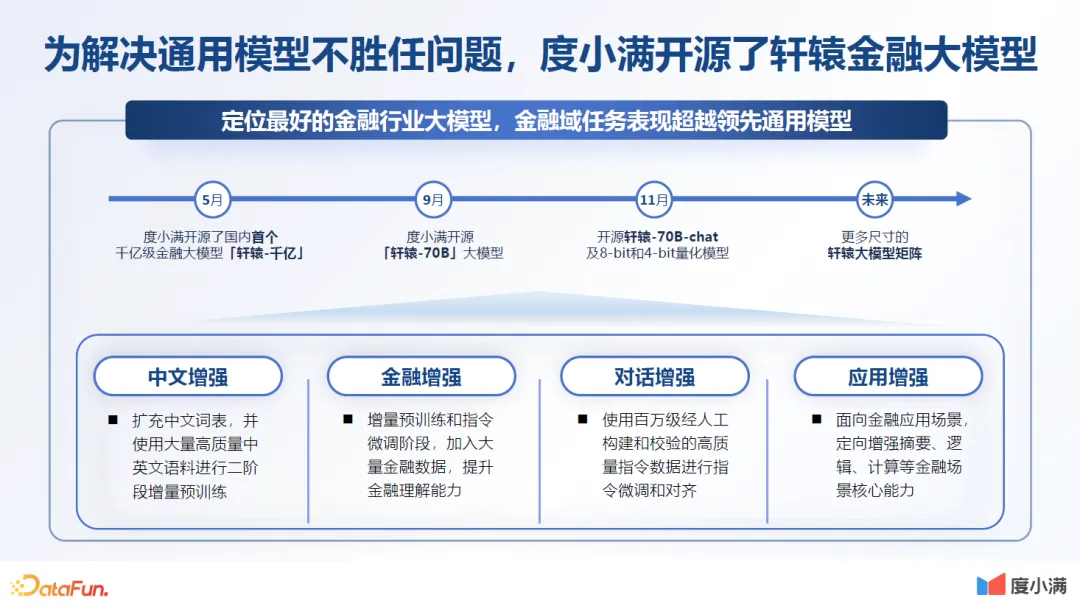
为解决上述通用大模型在金融领域的问题,包括成本问题等,我们自研金融大模型。我们对自研模型主要做了以下优化:
- 中文增强
- 金融增强
- 对话增强
- 应用增强
02 金融大模型的训练技术创新**
1.为大模型注入专业金融知识,训练专业金融能力
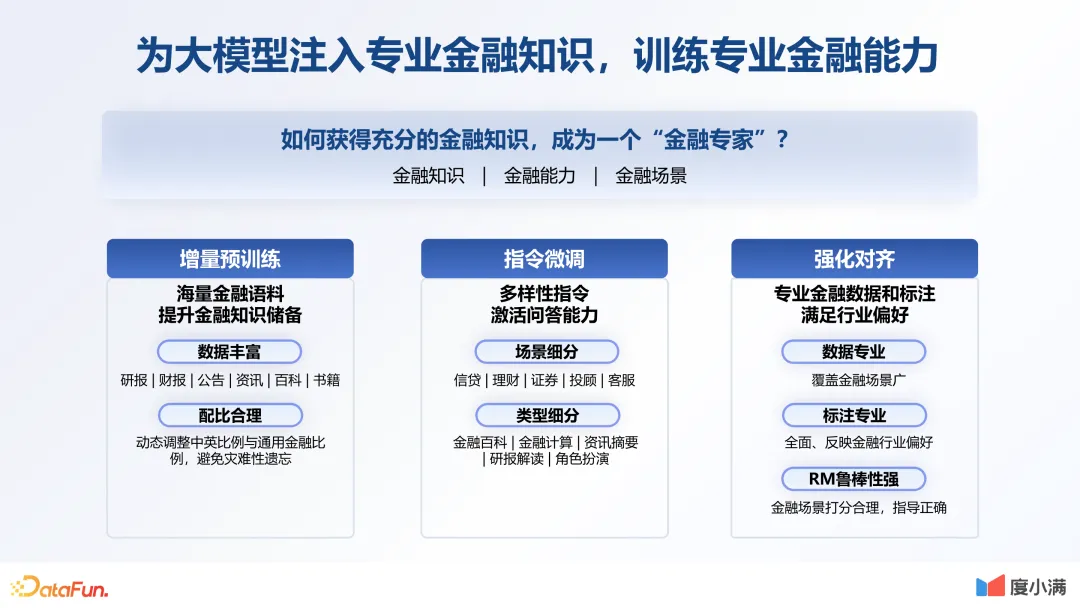
要提升大模型的金融专业能力,就要从小抓起,在它生命的每一个阶段,注入专业的知识体系。在预训练阶段,增加更丰富的金融语料,提升金融知识储备;在指令微调阶段,也要扩充不同场景的指令;在对齐环节,保证专业的金融数据和标注,满足行业偏好。接下来具体介绍其中的每个部分。
- 数据准备:
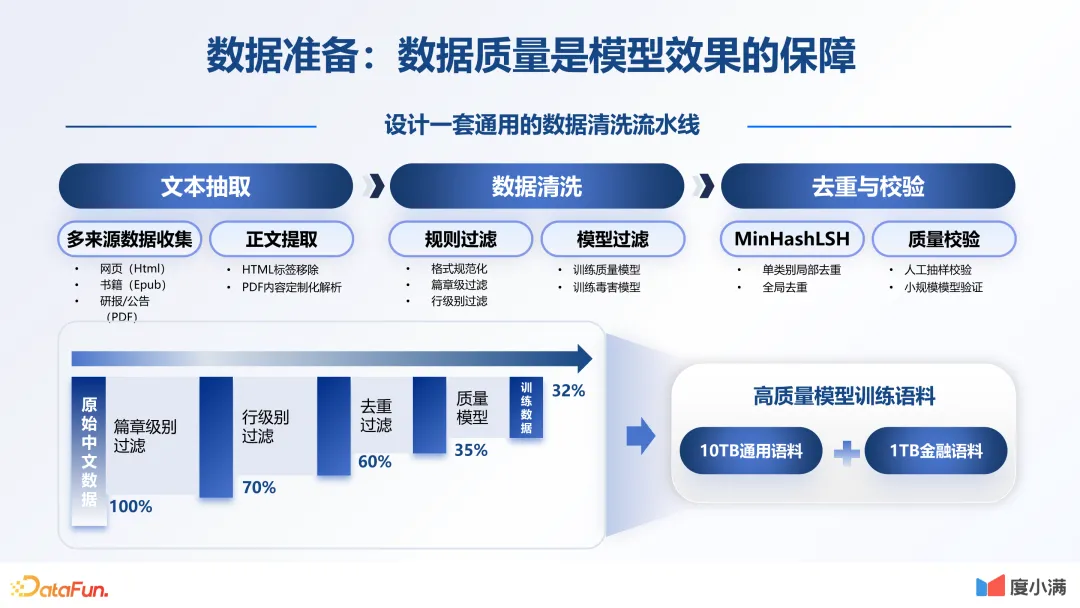
数据质量是模型效果的保障。首先数据要丰富,这是必备的条件。我们在这一环节做了非常多的工作,也设计了一套通用的数据流水线。从文本的抽取到数据的清洗,再到最后做一些人工的校验和评估,不断反复迭代。原始的中文数据,通过篇章级的过滤,一直到最后质量模型的排序,大概可以形成 32% 的中文数据。最后,形成了 10TB 的通用语料,加上 1TB 的金融语料。当然我们还在做更多的数据,特别是一些行业领域内专有数据的清洗。
- 增量预训练:
在数据准备完之后,就要去做预训练。需要针对中文场景做词表构建,对此,行业内大概有两种解决方案。一种是通过字粒度去扩充,因为汉字只看一个单词的话相对有限,大概数量是 5K 到 8K。另外一种就是很多中文大模型所采用的方法,即大量引入中文词汇,这样词表会比较大。考虑到对原有模型要尽量减少破坏,所以我们最终采用了字粒度扩容的方式,加入了 7K 的中文字符。这使得我们的整个词表大小达到 39K,词表压缩率为 48%。
在预训练阶段词表优化完之后,训练采用的是两阶段的优化方式,使得收敛更加稳定。第一阶段主要还是解决新加词表的泛化能力,我们仅更新模型词表的 embedding 以及解码线性层,使模型能够适应新的词表。在整个过程中,数据分布与原始的数据分布基本是一致的,就是为了保证模型的稳定性。在训练过程中我们发现,通过少量数据,能够使模型的 loss 达到平稳。所以第一阶段只训练了 40B 的 token。第二阶段对模型进行全量的更新,这时会训练大量的中文语料和英文语料。在这一阶段,我们训练了 300B 的 token。
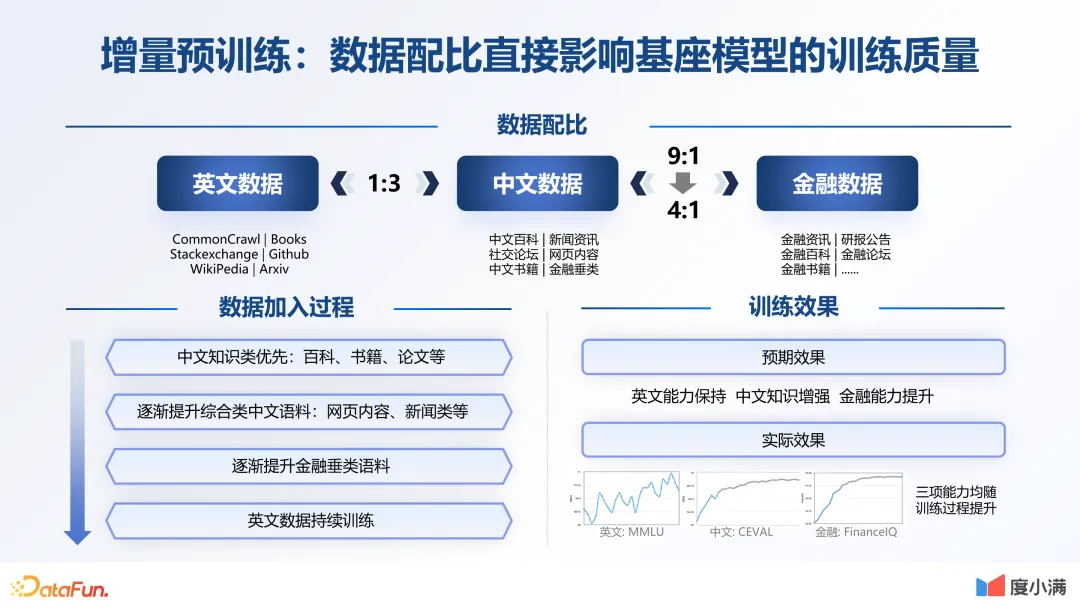
数据配比直接影响基座模型的训练质量。开始时整体的中英语料是 3 比 1。在英文数据上,一开始仅加入了少量的金融数据。随着整个训练过程的不断优化,金融数据的比例也越来越高。在训练过程中,要保证原有的英文能力。
- 指令微调:SFT 数据的丰富性和多样性直接影响对齐效果。在数据生成上,分为通用数据生成和金融专业领域数据生成。整体配比大概是 4 比 1。我们通过不同方式的自动生成以及人工改写,最后生成一个包含许多种类的 SFT 数据结果。

采用两阶段指令微调,保证通用能力的同时,提升金融问答能力。第一阶段是通过混合微调,用海量开源指令数据,同时加入一些预训练数据,保证其泛化性,并且可以有效减少幻觉问题。第二阶段是通过高质量的指令微调数据,提升整体的对话能力。整体的训练方式与预训练是一致的。
2.价值对齐:通过强化学习对齐价值偏好
接下来要做的是价值对齐,就是使模型的三观与我们一致,我们使用强化学习技术来对齐价值偏好。首先基于人类反馈做 reward model,这里我们选择 pair wise 的方式,并通过大量的人工标注排序。之后用 PPO 算法进行优化。未来,价值对齐会是做大模型非常核心的一个壁垒。
3.应用增强:升级系统工程,弥补大模型本身能力欠缺
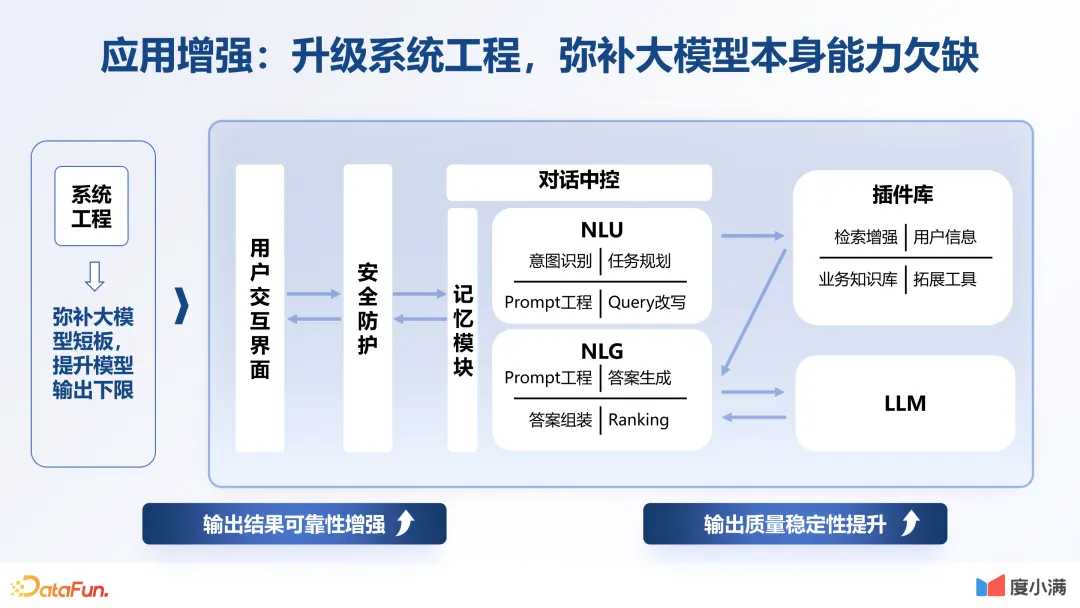
在数据微调以及价值对齐后,非常重要的一点是大模型与应用相结合、相绑定,因为所有模型的构建都是为了解决企业实际的问题。为了更好地为业务服务,需要提升大模型的整体能力,比如计算能力、多轮对话以及分析的能力等等。
4.工程优化:大模型训练效率面临诸多瓶颈
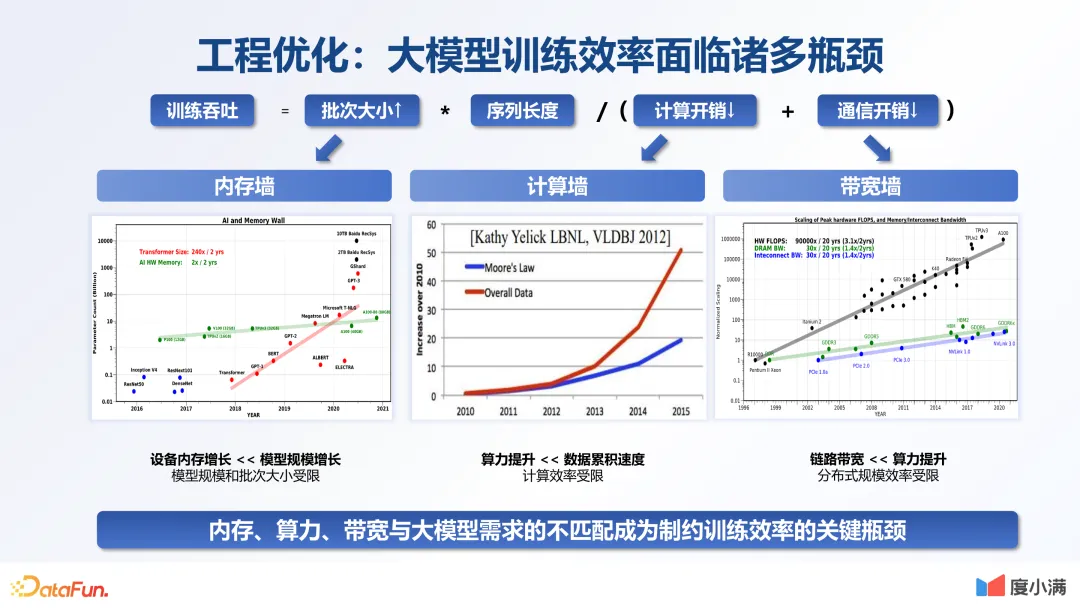
当前算力带宽的发展与模型参数的扩大是不匹配的。如何通过技术手段解决这一问题,是一个关键瓶颈,在这方面当时我们也做了很多探索。
- 突破内存与计算墙,提高训练吞吐。比如提升 batch size,优化模型占用显存的比例。通用的方式是 ZERO 的方式。在实践过程中,我们根据不同的方法来做不同的适配,并做不同算子的优化。通过优化,显存占用比例降低了 87%,batch size 提升了三倍,整体的训练吞吐能力提升了 36%。另外是计算复杂度,行业内用的比较多的是 Flash Attention,我们优化了很多底层算子,使用效率也有大幅提升。充分优化后,整体的训练吞吐比原来提升了 26%。
- 打破带宽墙,提升分布式效率。除了前面讲的内存以及计算复杂度的优化,另外一个重点是通讯效率的优化。通讯效率的优化包括算法和硬件两方面。算法方面,通过不同的算法提升 IO 效率,在金融行业用的比较多。另外在硬件上也可以做非常多的优化。目前我们搭了一个高速的网络,最高能支持八千多张卡,单机吞吐 800G。整体训练效率提升了三倍。另外,在做 GPU 分布式优化的时候,一个关键指标就是随着集群规模的扩大,单卡的 ROI 是否有折损。因为随着集群的扩大,通讯会变得越来越复杂,一个单卡的效率会变低。我们在 512 张卡以上规模的集群,整体的吞吐加速比基本是线性的,在 640 张卡下仍然可以达到 94%。
03 金融大模型的评测方法创新
对于大模型来说,评估体系是非常重要的。如何设计考察的内容和题目,是至关重要的一个工作。
1.大模型评测难题:主流榜单可靠性受质疑力
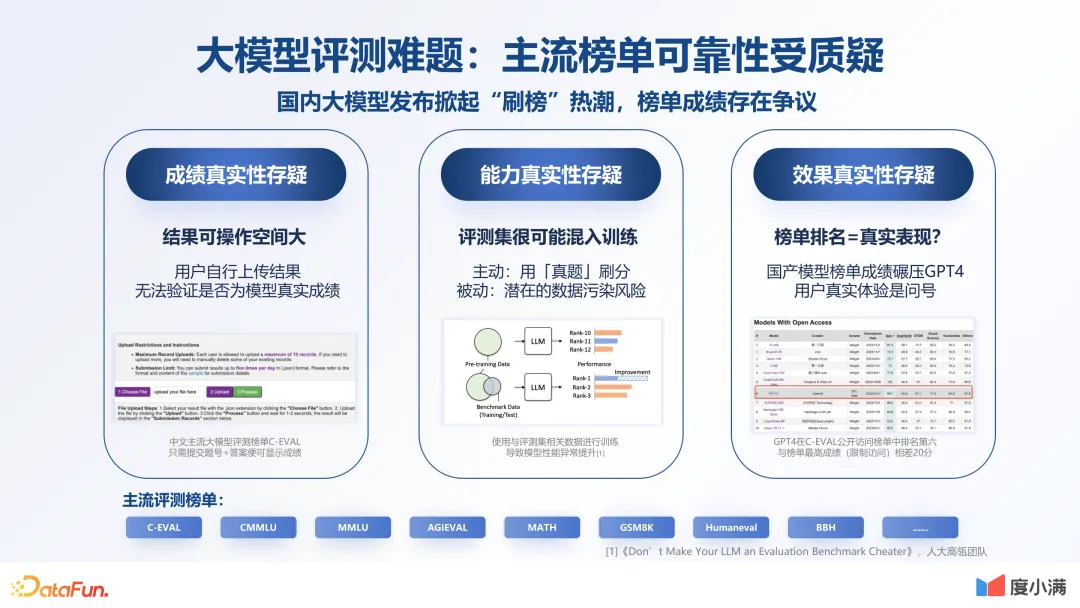
现在国内很多榜单是公开的,但是确实只能作为参考,不是说它没有意义,它起到了指引方向的作用。但在做大模型的过程中,要明晰大模型的每一个环节,明确每一步大模型能力的目标。如果训练一个模型,过了很长时间到结尾的时候才看到它的效果不佳,再去返工,那么造成的损失会是非常巨大的。
2.拒绝榜单绑架,用评测指引模型优化方向

我们自己的评估体系是横评看差距,纵评看提升。横评是在每个环节看不同模型在各个项目上的优劣。纵评是看同一模型在不同阶段、不同版本,甚至不同优化方式下的效果。
3.预训练阶段:评测指标走势判断是否符合预期
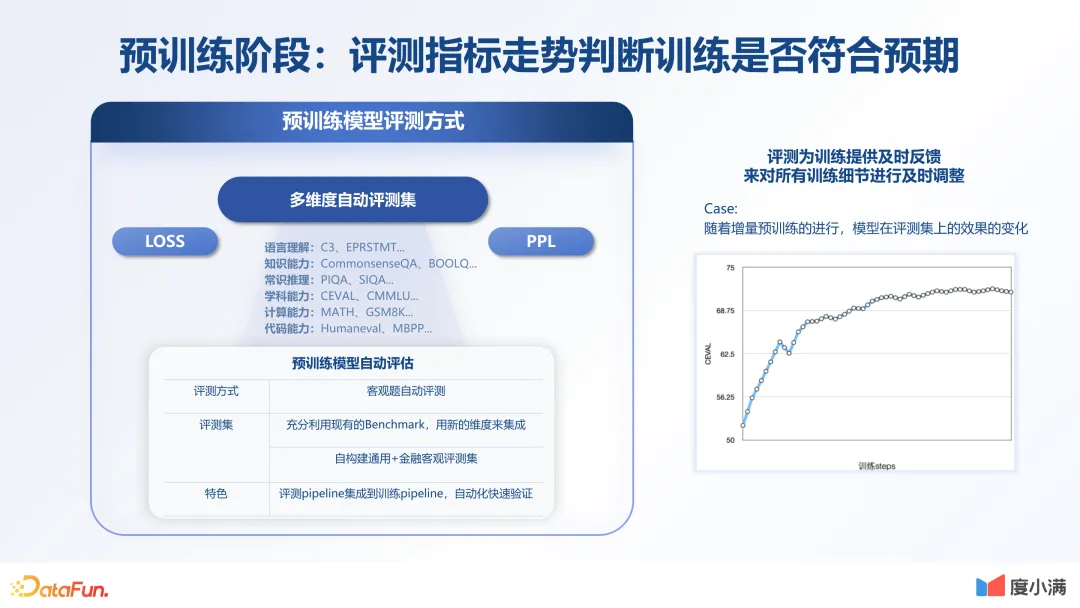
针对每个环节,我们也做了非常多的评测体系。首先是通用知识的预训练环节,有多维度的自动评测集。除了看 loss 之外,还会看其他 NLP 相关评测指标。也会看它在新的未知数据下的 PPL。对于每个评测指标,会在整个训练过程中进行实时地监控。
4.微调阶段:全面评估大模型“涌现”出的新能力

在微调阶段,因为有对话测评,所以除了自动化的评估之外,也需要更多的人工介入。我们制定了非常多的人工评测方法,以保证整个对话的效果是完全符合预期的。
5.强化阶段:评估相较微调阶段是否有能力提升

在强化阶段,主要是看两方面的标准,一方面经过强化学习之后,模型本身能力不能下降;另一方面是在安全性、有用性和稳定性这三个指标上要有明显提升,保证整个强化阶段达到预期。
6.从模型训练到场景落地:像评测人一样测评大模型
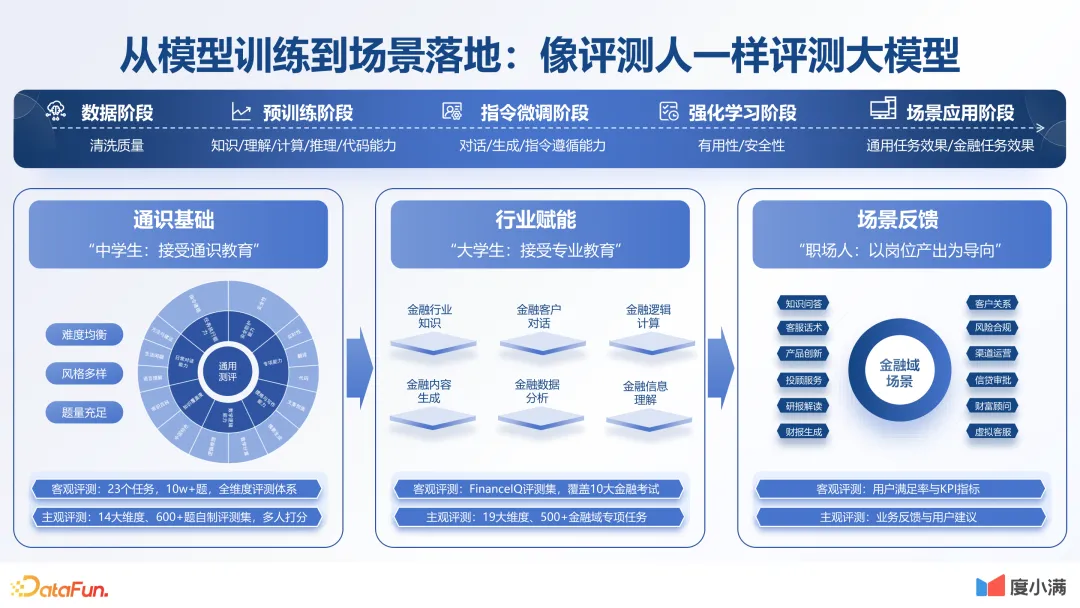
无论是从大模型整体的训练,还是从大模型评测,我们都要像看人一样去看它。我们希望能够构建一个更加丰富完善的评测体系,去评估出大模型的各项能力,整个体系也在不断优化中。
04 金融大模型的应用实践创新
最后介绍一下金融行业大模型应用方面的探索。
1.营销:个性化素材结合差异产品,重塑开放获客新模式
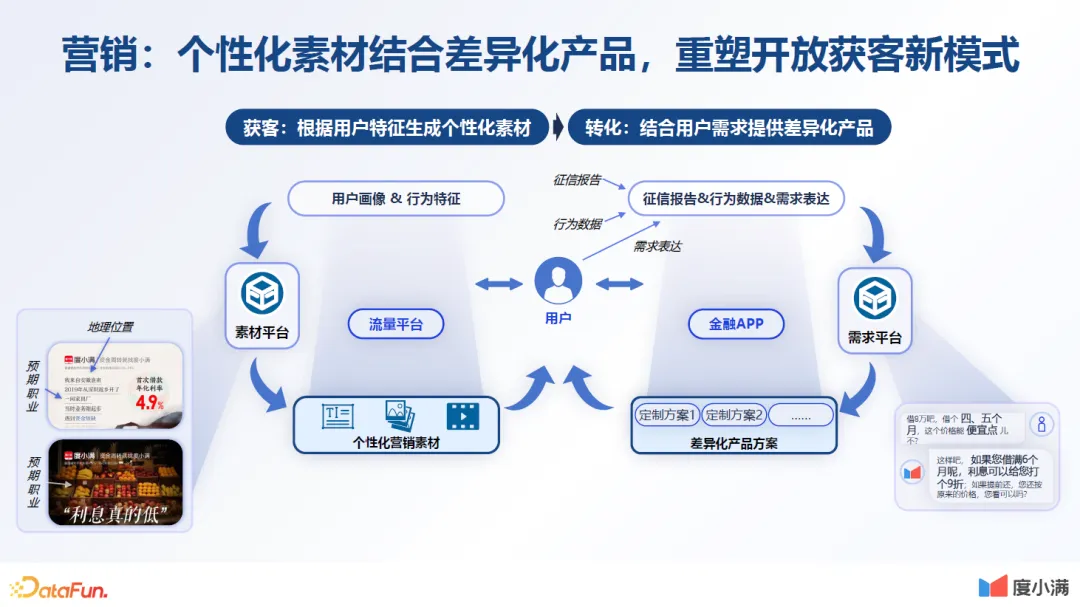
第一个是通过大模型的生产能力,使营销获客的效率大幅提升。获客是所有行业的一大难点。之前我们很难做到差异化的获客,因为要给用户展示不同的文案广告,要实时获取用户的需求,特别像文案广告这种内容,如果是通过设计师去做的话,可能需要几小时或者天级。而通过大模型,可以实时地获取用户画像,然后实时地生成用户所需的内容。
2.服务:体质降本,营销服务一体化
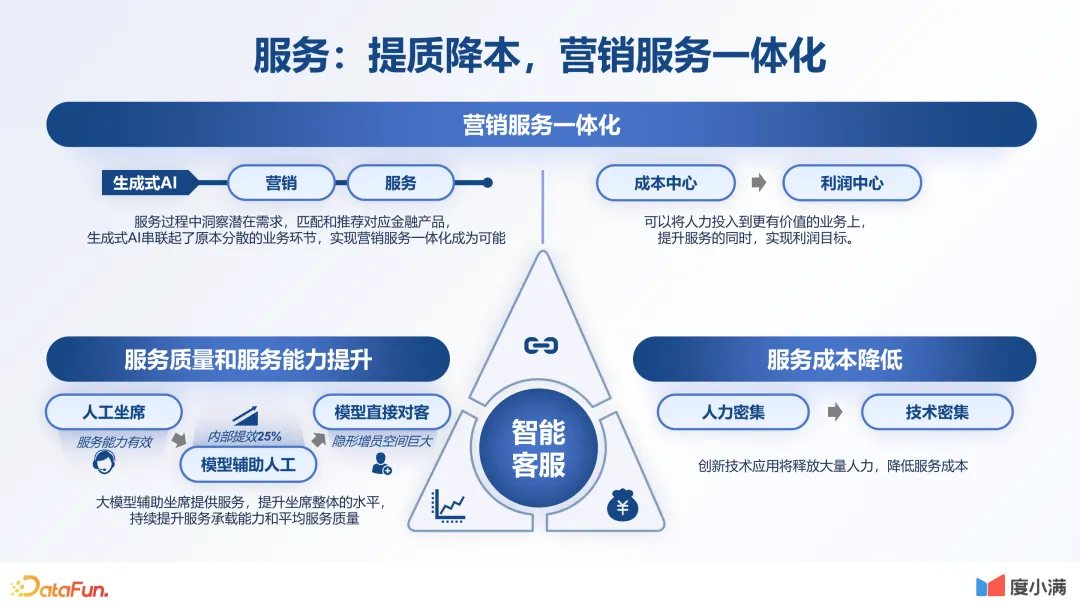
第二个应用场景是服务。传统的机器人很难做到人与机器自然地交流。大模型出来之后,提高了对话能力的天花板。之前做不到的事情,现在能做到了。未来人与机器的自然交流成为了可能。我们在这方面也做了很多探索,比如让大模型辅助人工客服,获得了 25% 的提效。
另外,我们也找了一些简单的小场景,让大模型全面替代人工客服,当然在保证质量的同时,不能有客诉。未来大模型会为企业整体的效率提升和成本降低带来大幅改善。
3.运营:数据驱动的业务运营新范式
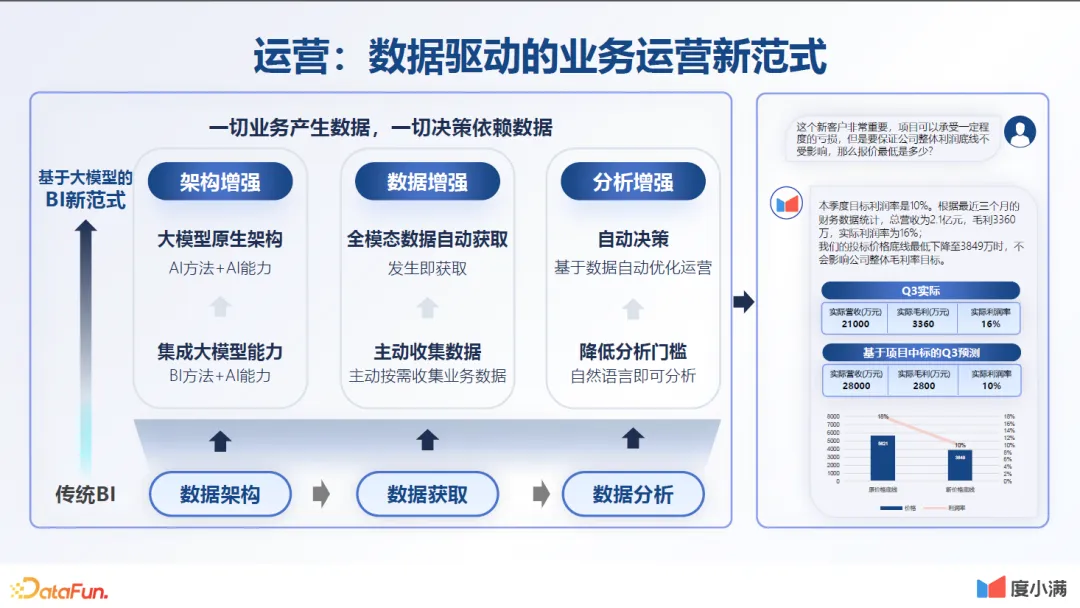
第三个应用是运营。因为金融行业是一个数据驱动的行业,每天要做非常多的经济指标统计、业务指标统计、报表分析,并基于此做各种预测。分析预测的质量取决于数据科学家,而数据科学家能力不一,结果可能存在差异,因此需要大量的数据对齐和认知对齐工作。如果利用大模型,能够统一标准,从而大幅提升决策效率。
4.办公:无处不在、无缝衔接的办公助手

第四个应用是智能办公。大模型能够提升员工获取知识的效率,帮助每一个员工提升个人角色的能力。当你到一家新公司,一个新行业,很多知识是不知道的,这时就可以直接咨询辅助助手,获得详细的专业知识,帮助你快速进入角色。
5.风控:提升感知和决策能力,智能风控更主动更实时
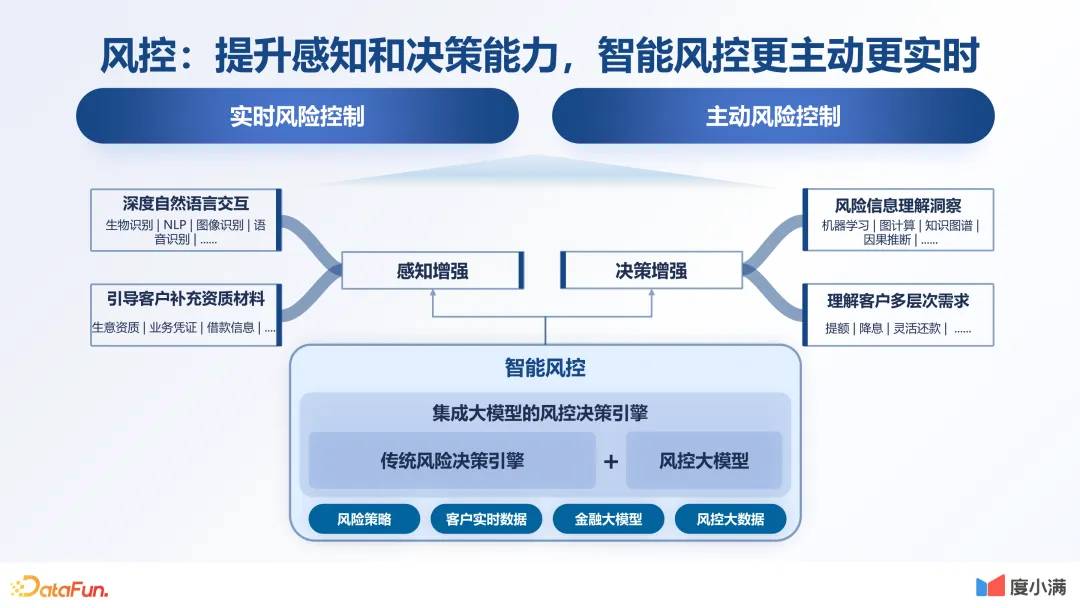
最后要讲的应用场景是风控,这是与金融强相关的一个场景。风险控制是金融领域的核心问题之一,而风险本身是一个决策问题,通过大模型,可以将其理解和处理数据的能力与原有的决策式风控相结合,使风控能力得到进一步加强。
05 总结:金融大模型迭代路径
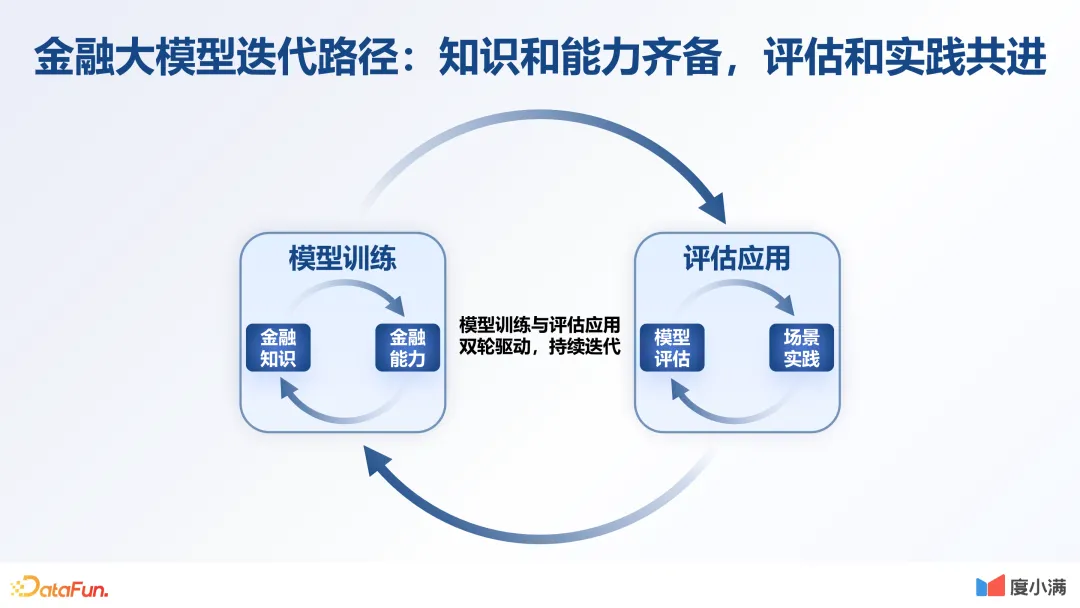
最后对前面的介绍做一个简单的总结,介绍一下大模型的迭代路径。大模型的迭代应该是模型训练与评估应用双轮驱动,持续迭代的。就像我们每个员工一样,在你的工作场景中要持续地学习创新,保持好奇心,得到工作反馈,再根据反馈不断进步。



